A majority of the world's online websites we use, constantly interact with the internet, whether it be on mobile or through web applications.
Most communications made through the internet are made using Web Requests through the HTTP protocol, which is an application-level protocol used to access World-Wide-Web resources.
The HTTP Protocol consists of communications between the client (Browser) and the server (Web Server). The client will request a resource from the web server, (Typically through port 80) that request will be processed and the requested resource returned. Assuming status is 200 OK.
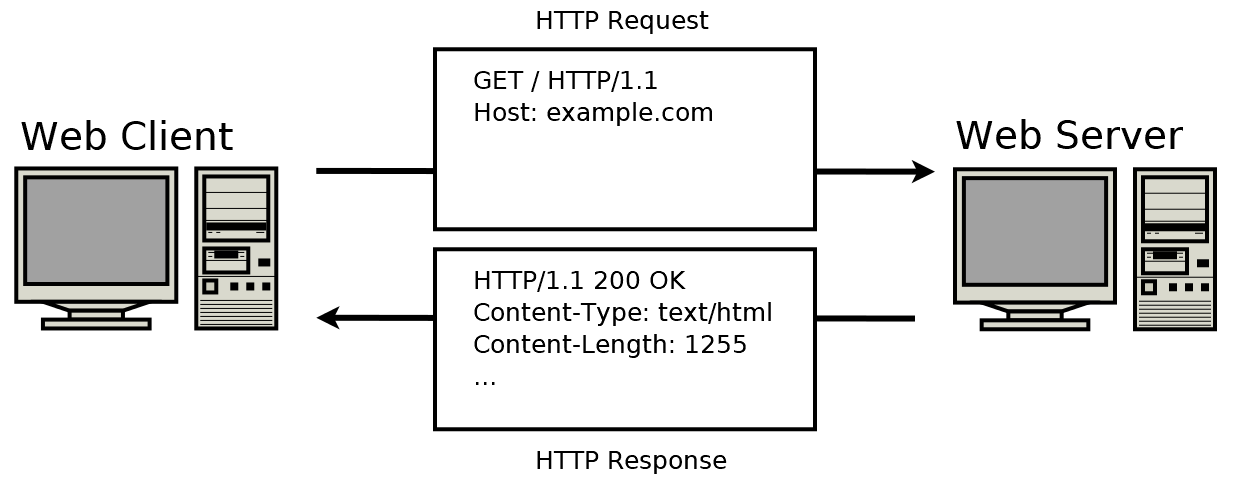
HTTP Request Example
Uniform Resource Locator (URL)¶
HTTP requests are utilised when a browser is used to access different websites on the internet. We enter a Fully Qualified Domain Name (FQDN) as a Uniform Resource Locator (URL) to reach the desired website.
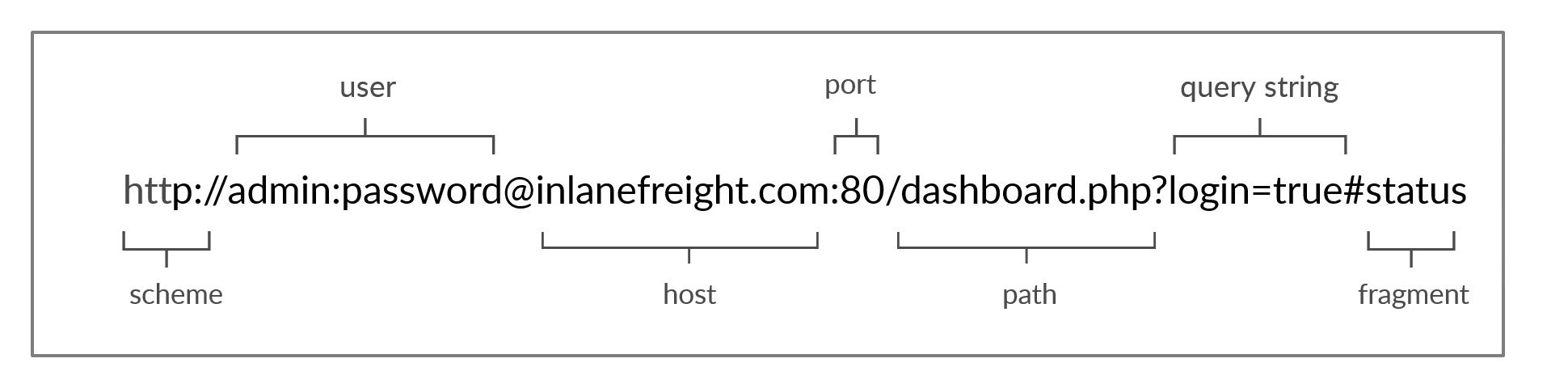
Image of the URL structure
The URL offers far more options to specify if we want, than just the desired website.
| Components | Example | Purpose |
|---|---|---|
| Scheme | http://, https:// | Identifies the protocol being used by the client. Ends with :// |
| User Info | admin:password@ | This is an optional component that contains the credentials (separated by a colon :) used to authenticate to the host, separated from the host with an at sign (@). |
| Host | inlanefreight.com | The host signifies the resource location. This can be a hostname or an IP address. |
| Port | :80 | The Port is separated from the Host by a colon (:). If no port is specified, http schemes default to port 80 and https default to port 443. |
| Path | /dashboard.php | This points to the resource being accessed, which can be a file or a folder. If there is no path specified, the server returns the default index (e.g., index.html). |
| Query String | ?login=true | The query string starts with a question mark (?), and consists of a parameter (e.g., login) and a value (e.g., true). Multiple parameters can be separated by an ampersand (&). |
| Fragments | #status | Fragments are processed by the browsers on the client-side to locate sections within the primary resource (e.g., a header or section on the page). |
| Not all components are required for accessing a resource over HTTP using a URL. |
Mandatory URL Components:
- Scheme:
https:// - Host:
google.com
These are requirements as without them there would have no resource to request.
Optional URL Components:
- User Info:
Username:Password - Port:
(Defaults) HTTP:80 HTTPS:443 - Path:
/index.html - Query String:
?parameter=value - Fragments:
#banner
HTTP Flow¶
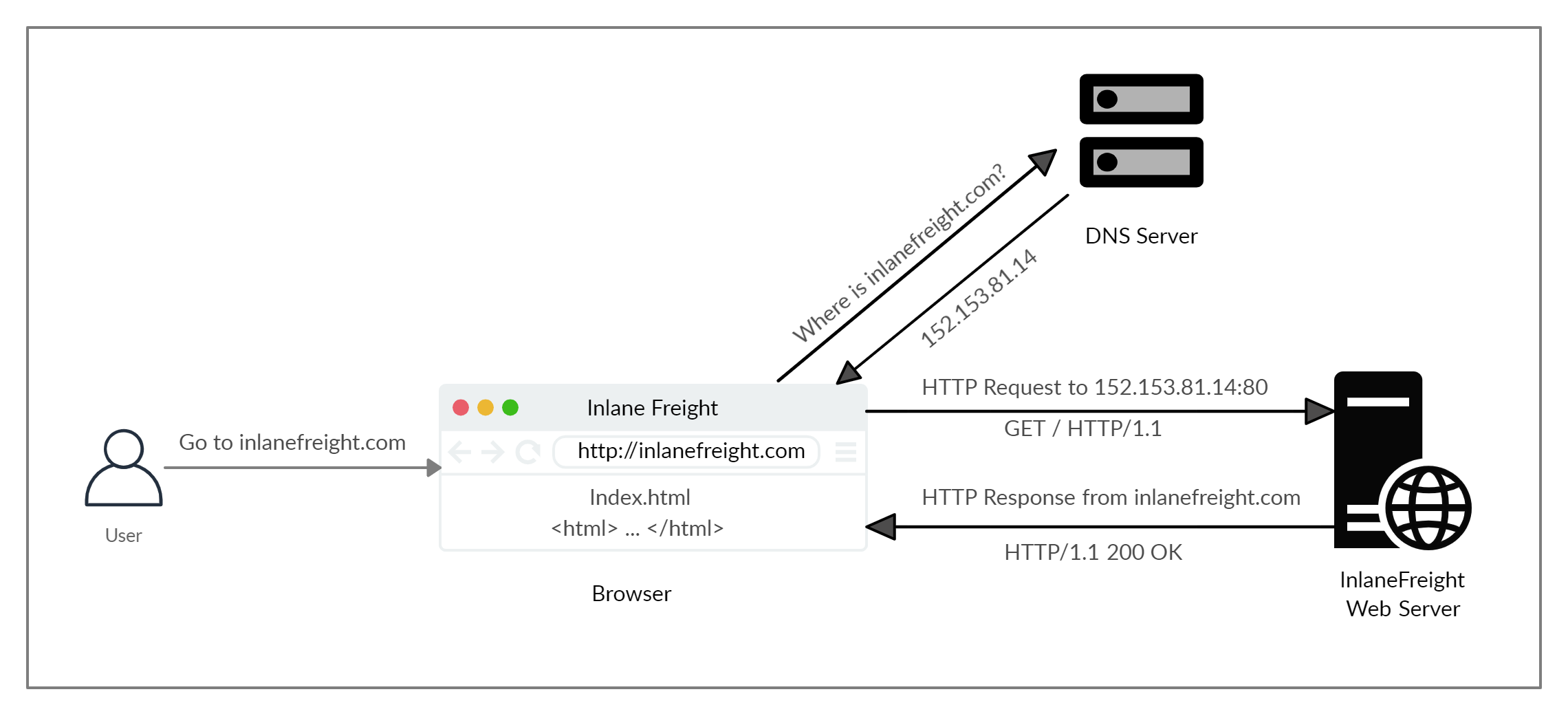
High-Level HTTP Flow Diagram
When a user enters a URL into the browser, the browser sends a request to a DNS (Domain Name System) server to resolve the domain name (https://google.com) and get its corresponding IP address (8.8.8.8).
The DNS Server looks up the domain to locate its IP address and returns it. All domain names need to be resolved. A server cannot communicate without an IP Address.
On Linux based systems the browser will first look up records in '/etc/hosts' file. In the event, that the requested domain does not exist within it, then the browser will contact other external DNS servers in an attempt to resolve the IP.
Records can be added manually to '/etc/hosts' for DNS resolution by adding their IP followed by their domain name.
e.g: /etc/hosts
127.0.0.1 localhost
192.168.1.24 gateway
Once the browser obtains the IP address linked to the requested domain it performs a GET request to the default HTTP port 80, requesting the root "/" path. Once the request is received the web server processes it and sends a response back.
By default, servers are configured to return an index page (e.g., index.html or index.php) when a request is received for the root path.
The response also contains a status code, which indicates the result of the HTTP request:
- 200 OK: The request was successful, and the server returned the requested resource.
- 404 NOT FOUND: The requested resource could not be found on the server.
- 403 FORBIDDEN: The server understood the request, but access to the resource is forbidden.
Once the request has been successfully, been made and the client has received the response, the client (browser) will then render the contents of the index page (e.g., index.html or index.php) to present them to the user.
cURL¶
Two important tools that can be utilised by the penetration tester are:
- Web Browser, like Chrome, Edge, DuckDuckGo, Opera, or FireFox)
- cURL command line tool.
cURL (Client URL) is a command-line utility and library that primarily supports HTTP along with many other protocols such as HTTPS, IMAP, POP3, SCP, SFTP, FTP and Many More.
Due to this compatibility to communicate with a vast number of essential protocols, it makes a good choice for scripts as well as automation, making it easier to send various types of web requests from the command line.
$ curl example.com
Perform a basic **HTTP Request** to 'example.com' by passing the URL as an **argument** to the **cURL** command.Unlike a web browser, cURL does not render the HTML/JavaScript/CSS code. Instead, it prints the output in its raw format. This allows penetration testers, primarily interested in the request and response context, to send requests more quickly and conveniently than with a web browser.
We can also use cURL to download a page or file and output the content into a file.
$ curl -O http://example.com/index.html
Example using the
-O (Output) flag.Remember to include "index.html" as -O parameter uses the file in the URL request as the name
As mentioned earlier, when accessing the root path (/), the server typically returns a default index page (200 OK) (e.g., index.html or index.php). Then the ls command is executed successfully, the index.html file should be downloaded on the system.
$ curl -o file.txt http://example.com/
We want to specify the output file name, we can use the
-o [Name] (output) flag Terminal Output:¶
$ curl -O example.com/index.html
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1256 100 1256 0 0 4250 0 --:--:-- --:--:-- --:--:-- 4243
cURL still processed some of the status into the terminal while processing the HTTP request. We can silent the status with the -s flag.
Finally cURL's help parameter -h which is available to show what options we may use with cURL.
$ curl -h
Usage: curl [options...] <url>
-d, --data <data> HTTP POST data
-h, --help <category> Get help for commands
-i, --include Include protocol response headers in the output
-o, --output <file> Write to file instead of stdout
-O, --remote-name Write output to a file named as the remote file
-s, --silent Silent mode
-u, --user <user:password> Server user and password
-A, --user-agent <name> Send User-Agent <name> to server
-v, --verbose Make the operation more talkative
For more information on cURL, we can also use the following commands:
$ curl --help-all
$ curl --help category (e.g http)
$ man curl
Exercises:¶
Q: To get the flag, start the above exercise, then use cURL to download the file returned by '/download.php' in the server shown above.
A: HTB{64$!c_cURL_u$3r}