CO3722 Data Science
CO3722 Lecture 9 - Guest Speaker
Lecture Documents¶
Written Notes¶
Learning Objectives¶
- Discuss problem statement by proposing hypotheses
- Create data visualisations using selected features of a dataset
- Evaluate data visualisations reflecting on hypotheses and problem statement
Case Study Example¶
Loan Prediction/Approval Dataset¶
- Provide guidance for summative assessment.
Example Data Science Project Journey, including:
- Examining datasets
- Asking questions and proposing hypotheses
- Visualise data
- Identifying outliers
- Consider algorithm design
- Algorithms - Semester 2
Questions/Hypothesis¶
What can affect loan approval?
- All customers over the age of 50 will be accepted for a loan
- Loan acceptance requires higher level of incomes
Task - Refer back to problem statement. Any other examples?
Recap: Understand/Describe Dataset¶
| Variable | Description | Corrected Type | Sub-Type |
|---|---|---|---|
| Loan ID | Unique Loan ID | Categorical | Nominal |
| Gender | Male/Female | Categorical | Nominal |
| Married | Applicant Married (Y/N) | Categorical | Nominal |
| Dependents | Number of Dependents | Numerical | Discrete |
| Education | Applicant Education (Graduate/Under Graduate) | Categorical | Ordinal |
| Self Employed | Self Employed (Y/N) | Categorical | Nominal |
| Applicant Income | Applicant Income | Numerical | Continuous |
| Co-Applicant Income | Co-Applicant Income | Numerical | Continuous |
| Loan Amount | Loan Amount in Thousands | Numerical | Continuous |
| Loan Amount Term | Term of Loan in Months | Numerical | Discrete |
| Credit History | Credit History meets Guidelines (1/0) | Categorical | Nominal |
| Property Area | Urban/Semi Urban/Rural | Categorical | Nominal |
| Loan Status | Loan Approved (Y/N) | Categorical | Nominal |
Recap: Bivariant Analysis¶
Slides copied from previous lecture as below:
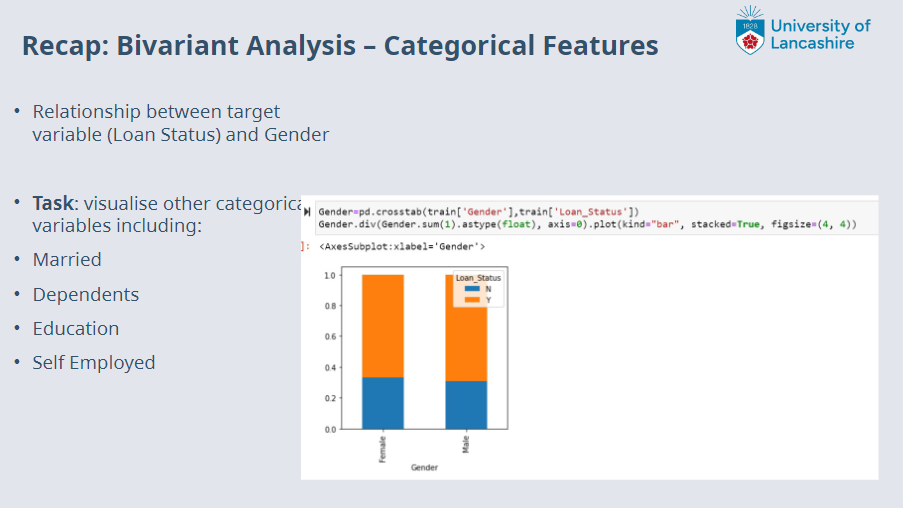
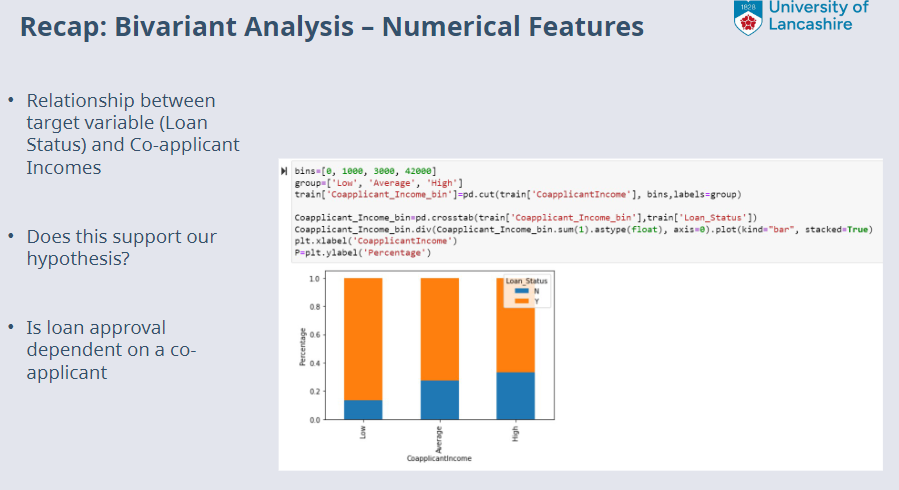
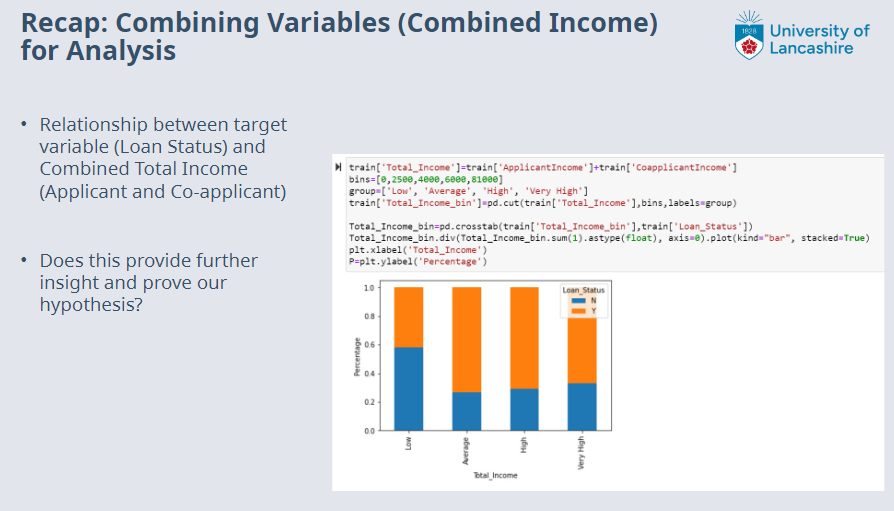
Missing/Outlier Data?¶
- Impact of missing data and outliers
- Has any missing data been identified?
Feature-Wise - Count of Missing Data¶
- There are missing values in all features
- Consider numerical and categorical features
- Imputation using mean, median and mode
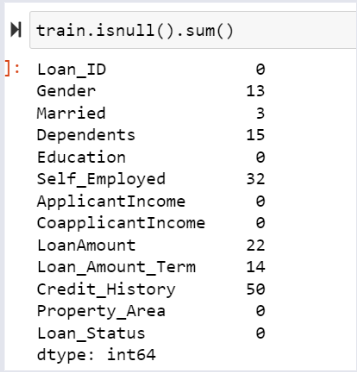
Filling Missing Values¶
- There are some other categories with missing values...
- Could generalise here using the mode.
Task
- Consider all categories with missing data and amend?
- Make appropriate judgements here...
- Loan Amount has missing values could mean be used here?
- Are there any outliers which could impact the value of the mean?
- What about other statistical measures such as median?
- Carry out a check to see if there are any other missing values.
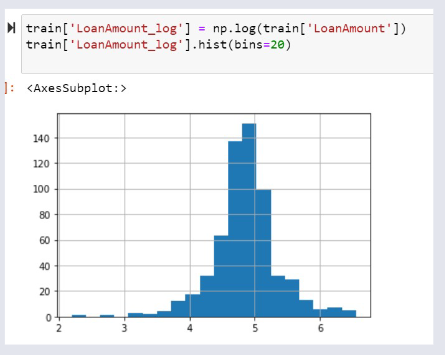
Loan Amount - Normal Distribution¶
Evidence of outliers? Use a histogram to view distribution. Is the distribution symmetric or skewed?
Attempt 'Log Transformation' to produce a 'more' normal distribution. Does not affect smaller values but does reduce larger values.
Log Transformation¶
Semester 2 - Next Steps¶
- Build a Data Science Model E.g. Linear/Logistic Regression.
- Build and make predictions using 'Test' dataset.
Consider...¶

Data Modelling Algorithms¶
- Linear Regression
- Logistic Regression (Classification)
- Decision Tree (Random Forests)
- Unsupervised Learning (Clustering)
Discuss - What is known so far from research?
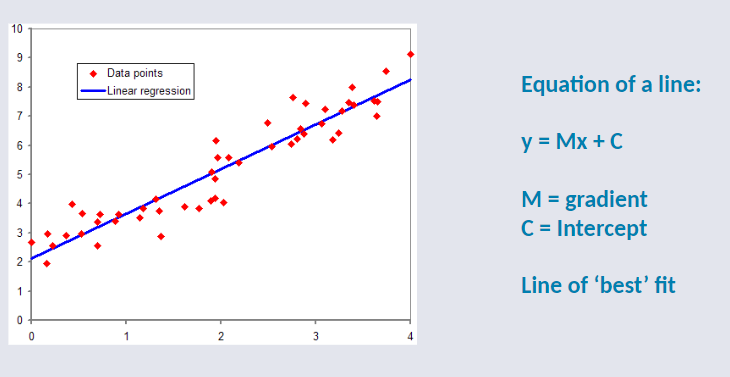
Linear Regression - Supervised Learning¶
Assignment 2 - Next Steps¶
Keep Asking Questions:
- Does my data make sense?
- Is the data consistent?
- What can be evaluated from the data's distribution? Does it change over time? Is this to be expected?
- Use visualisations to help. Is data normalisation needed first?
- Is the data complete? Any missing data or anomalies?
- Do you understand the features? Any data transformations required? (i.e. datatypes)
- Balanced or unbalanced data? Require a 50/50 split. Consider undersampling and oversampling
- any additional data that might be beneficial?
Future Steps¶
Consider:
- Metric for evaluation - What is meant by a 'good' model?
- Splitting data - Training and Testing sets (import train_test_split)